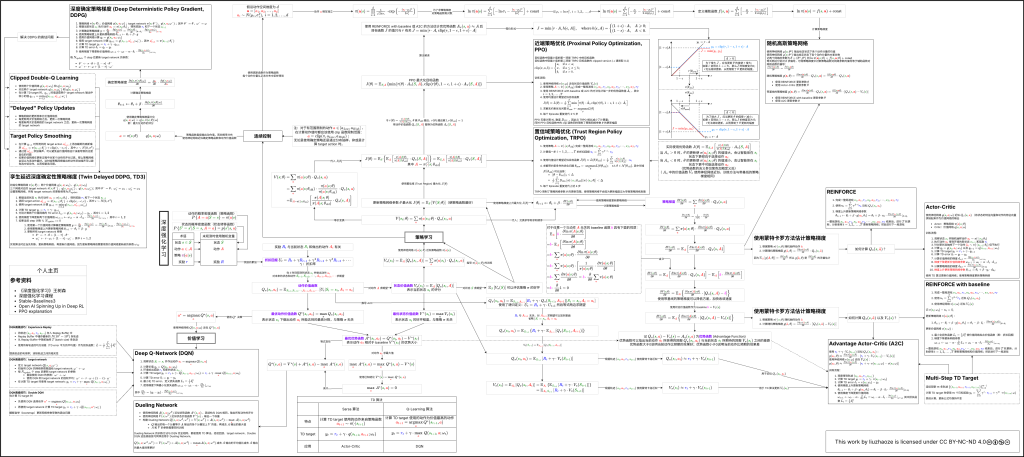
介绍
本图展示了深度强化学习涉及到的大部分概念的关系,包括:
- 状态、动作、奖励、折扣回报
- 动作价值函数、状态价值函数、优势函数
- 最优动作价值函数、最优状态价值函数、最优优势函数
同时,本图还展示了深度强化学习中大部分算法的数学推导以及训练方法,包括:
- 价值学习
- 离散动作空间
- DQN
- Dueling Network
- 离散动作空间
- 策略学习
- 离散动作空间
- REINFORCE
- Actor-Critic
- REINFORCE with Baseline
- Advantage Actor-Critic (A2C)
- TRPO
- PPO
- 连续动作空间
- DDPG
- TD3
- 随机高斯策略网络
- 离散动作空间
使用方法
配合王树森深度强化学习课程使用。
下图对阅读顺序进行了标注:
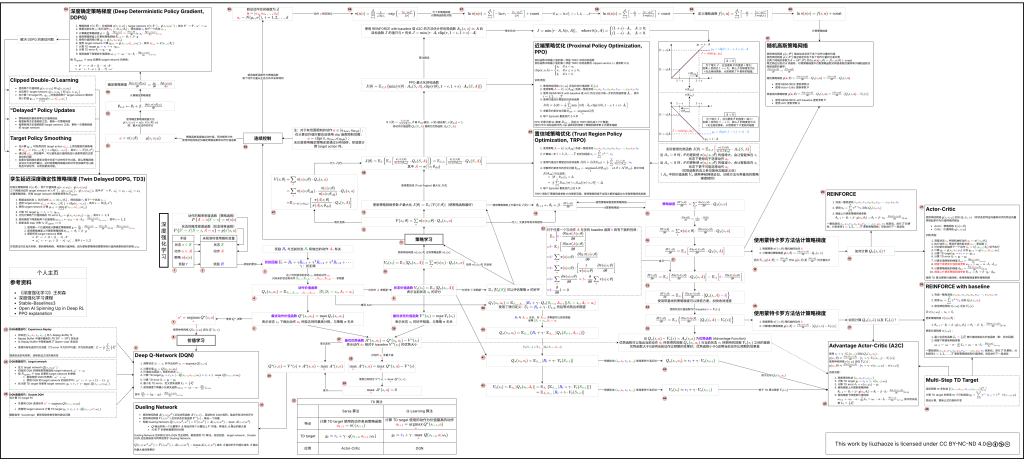
每节课程所涉及的节点标号如下所示:
- Overview.
- Reinforcement Learning
[1-6]. - Value-Based Learning
[7-9]. - Policy-Based Learning
[10-20]. - Actor-Critic Methods
[21]. - AlphaGo.
- Reinforcement Learning
- TD Learning
[22].- Sarsa.
- Q-learning.
- Multi-Step TD Target.
- Advanced Topics on Value-Based Learning.
- Experience Replay (ER) & Prioritized ER
[23]. - Overestimation, Target Network, & Double DQN
[24]. - Dueling Networks
[25-30].
- Experience Replay (ER) & Prioritized ER
- Policy Gradient with Baseline.
- Policy Gradient with Baseline
[31-34]. - REINFORCE with Baseline
[35-37]. - Advantage Actor-Critic (A2C)
[38-44]. - REINFORCE versus A2C
[45].
- Policy Gradient with Baseline
- Advanced Topics on Policy-Based Learning.
- Trust-Region Policy Optimization (TRPO)
[46-48]. - Partial Observation and RNNs.
- Trust-Region Policy Optimization (TRPO)
- Dealing with Continuous Action Space.
- Discrete versus Continuous Control
[49]. - Deterministic Policy Gradient (DPG) for Continuous Control
[50-53]. - Stochastic Policy Gradient for Continuous Control
[54-60].
- Discrete versus Continuous Control
- Multi-Agent Reinforcement Learning.
- Basics and Challenges.
- Centralized VS Decentralized.

